Easy end-to-end guide for getting PostgreSQL with the pgvector extension up & running with Docker and using it as a vector store in n8n. Including sample workflows for storing extracted data from a PDF as OpenAI embeddings and querying it with a simple RAG agent.
There are many vector stores available like Pinecone or Chroma. But lots of them are either Cloud-hosted only and/or force you to deal with a complete new database system apart from traditional ones.
The pgvector extension delivers an interesting alternative as it turns a standard PostgreSQL database into a vector store. This enables you to run it locally as any other PostgreSQL instance, use the rich existing ecosystem to manage an maintain the database with tools you are used to like pgadmin. Also, the popular AI-automation tool n8n has built-in support for pgvector as a vector store.
In this article it is assumed that you have a basic knowledge on how to build n8n workflows with OpenAI. Our focus will be on the pgvector vector store.
So let’s get started and set up pgvector as a vector store and use it in n8n…
Table of Contents
Running pgvector using Docker
The easiest way to run pgvector is to use the available Docker image. The process of getting up&running is exactly the same as for a normal PostgreSQL Docker image. In this article we will follow the steps from the guide on how to run PostgreSQL with Docker locally using persistent storage as this is the most convenient way. Refer to this for any further detail not mentioned here.
# assumptions: you have already created...
# - a user and group "pgvector"
# - a local directory /var/db/pgvector owned by the pgvector user
$ docker pull pgvector/pgvector:pg16
$ docker run -d \
--user $(id -u pgvector) \
--name mypgvector \
-e POSTGRES_PASSWORD=Test123$ \
-e PGDATA=/var/lib/postgresql/data/pgdata \
-v /var/db/pgvector:/var/lib/postgresql/data:Z \
-p 5432:5432 \
pgvector/pgvector:pg16Preparing the vector store for using it with n8n
Now that PostgreSQL with pgvector is running in the container mypgvector, we’ll connect using psql and prepare everything to use the vector store in n8n. First let’s:
$ psql -h localhost -U postgres
psql (16.9)
postgres=# CREATE DATABASE vectors;
CREATE DATABASE
postgres=# CREATE USER vuser WITH ENCRYPTED PASSWORD 'Test123$';
CREATE ROLE
postgres=# GRANT ALL PRIVILEGES ON DATABASE vectors TO vuser;
GRANT
postgres=# \c vectors
vectors=# CREATE EXTENSION vector;
CREATE EXTENSION
vectors=# GRANT ALL PRIVILEGES ON SCHEMA public TO vuser;
GRANTAfter the new database vectors is created and prepard, we’ll connect directly to it using the new user and:
$ psql -h localhost -U vuser -d vectors
psql (16.9)
vectors=> \dx vector
List of installed extensions
Name | Version | Schema | Description
--------+---------+--------+------------------------------------------------------
vector | 0.8.0 | public | vector data type and ivfflat and hnsw access methods
(1 row)
vectors=> CREATE TABLE public.embeddings
(
id bigserial PRIMARY KEY,
embedding vector(3072) NOT NULL,
text text,
metadata jsonb
);
CREATE TABLE
The new table public.embeddings contains all the rows n8n is expecting when writing/reading the embeddings. In our example we will use the OpenAI text-embedding-3-large which uses a standard vector length of 3072. Make sure to adjust the vector length to the value appropriate value that’s required by the text embedding model that you will use.
We’re now ready to switch over to n8n and create a simple workflow to generate embeddings and store them in pgvector.
A simple n8n workflow to create and store embeddings in pgvector
Heading over to n8n, we’ll first create a simple workflow that creates embeddings out of a given PDF document using the OpenAI text embeddings and stores them in our pgvector we’ve just set up.
As solid sample data we’ll use the freely available Templeton 2024 funds report, which is very complex and has over 800 pages. We use the form upload node in n8n, followed by the Extract from file to get the text out of the PDF before creating and storing the embeddings. The complete workflow looks like this:
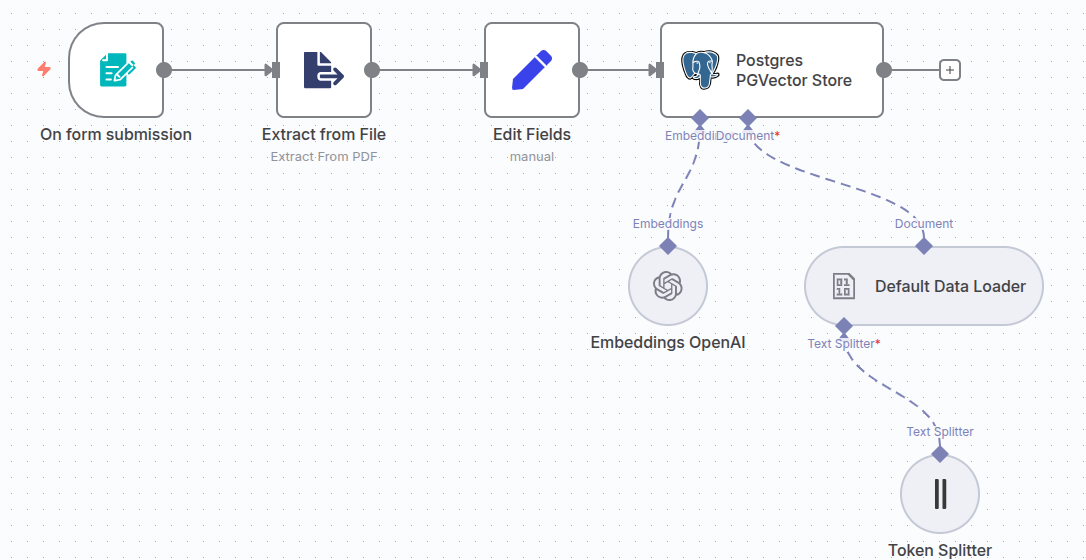
The workflow JSON is available for download here.
Make sure to choose text-embedding-3-large as the embedding model. In the token splitter select a chunk size of 1.000 and overlap of 250 for feasible results.
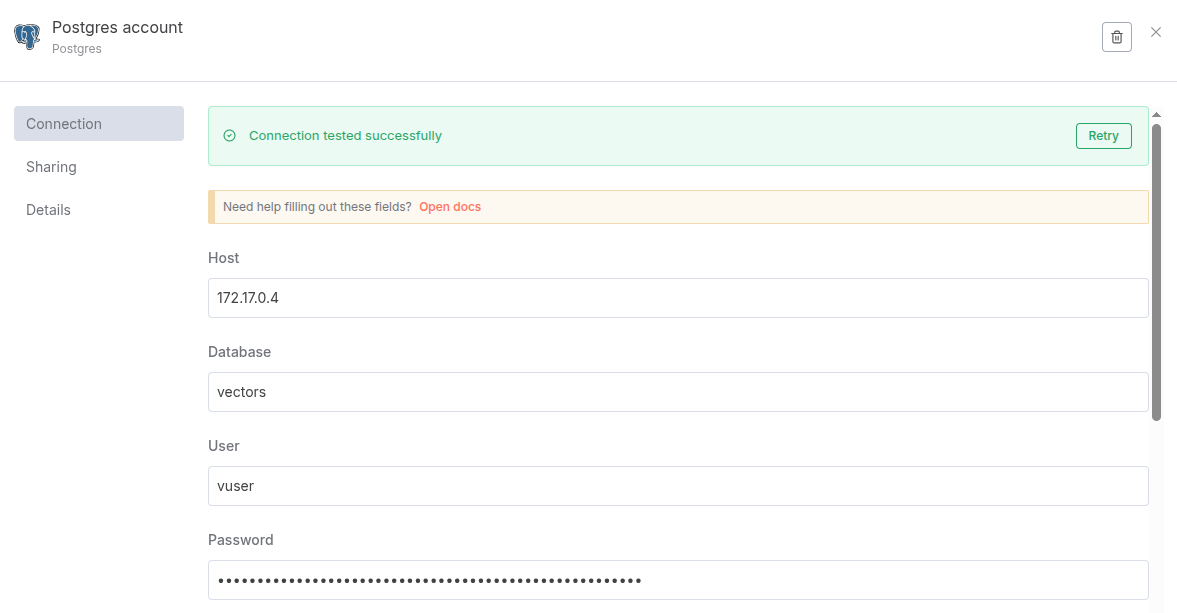
For the Postgres PGVector Store node, create new credentials using the database, username and password from the setup process before. For the host, choose depending on how you are running n8n:
Then run the workflow and verify the embeddings have been created.
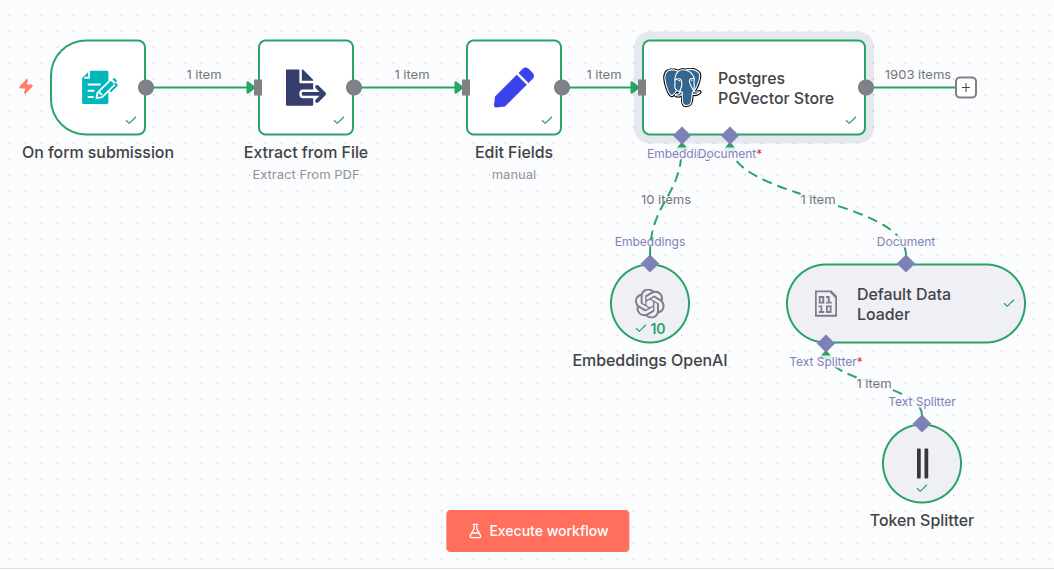
Verifying directly in the database…
vectors=> select count(*) from embeddings;
count
-------
1903
(1 row)
Excellent, we’re now ready to go on and create a simple RAG agent in n8n that uses our embeddings.
RAG agent example using pgvector as a tool
Finally, let’s create a simple RAG agent in n8n that uses our populated pgvector vector store to answer details about Templeton funds. This agent is absolutely straight foward:
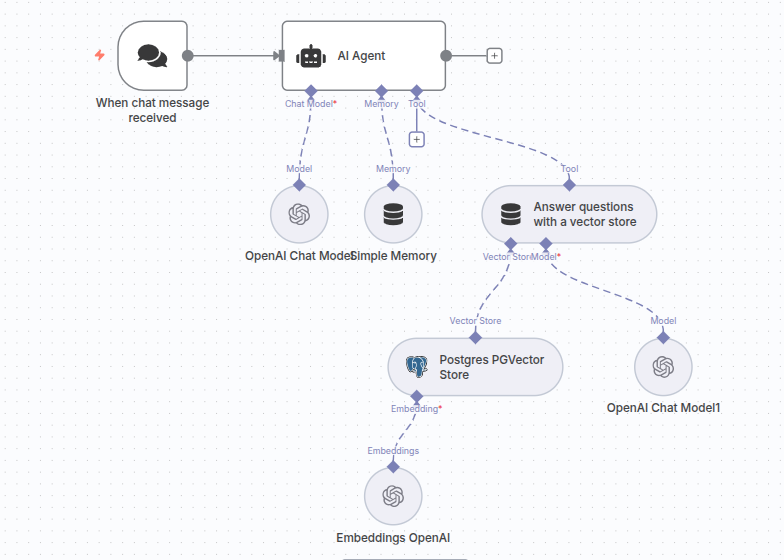
The workflow JSON is available for download here.
Make sure to use the previously created pgvector credentials and choose the text-embedding-3-large embedding model. The most exiting thing in this workflow is the system prompt in the AI Agent node.
You are an assistant for the analysis and determination of key figures and
information on Franklin Templeton funds. Your task is to answer questions on
this subject with the help of your vector database.
If you cannot answer a question with the help of your database or if the
question is unclear, answer accordingly.
Structure of your answers:
- Clear and to the point
- Provide specific figures and information that were requested
- Indicate from which document in the vector database you obtained the informationIn the example, gpt-4o was used as the model. For the Answer Questions node you could go with a simple description.
Delivers facts & figures about Templeton funds.That’s already it. You can now start your RAG agent and ask questions that will be answered using the pgvector vector store .

Happy prompting 🙂